Migración Multi-DB NBA
Pipeline ETL multi-fase sobre dataset NBA: modelado relacional en Oracle, cluster PostgreSQL de alta disponibilidad con replicación WAL + failover automático, y API REST de migración hacia MongoDB con persistencia políglota.
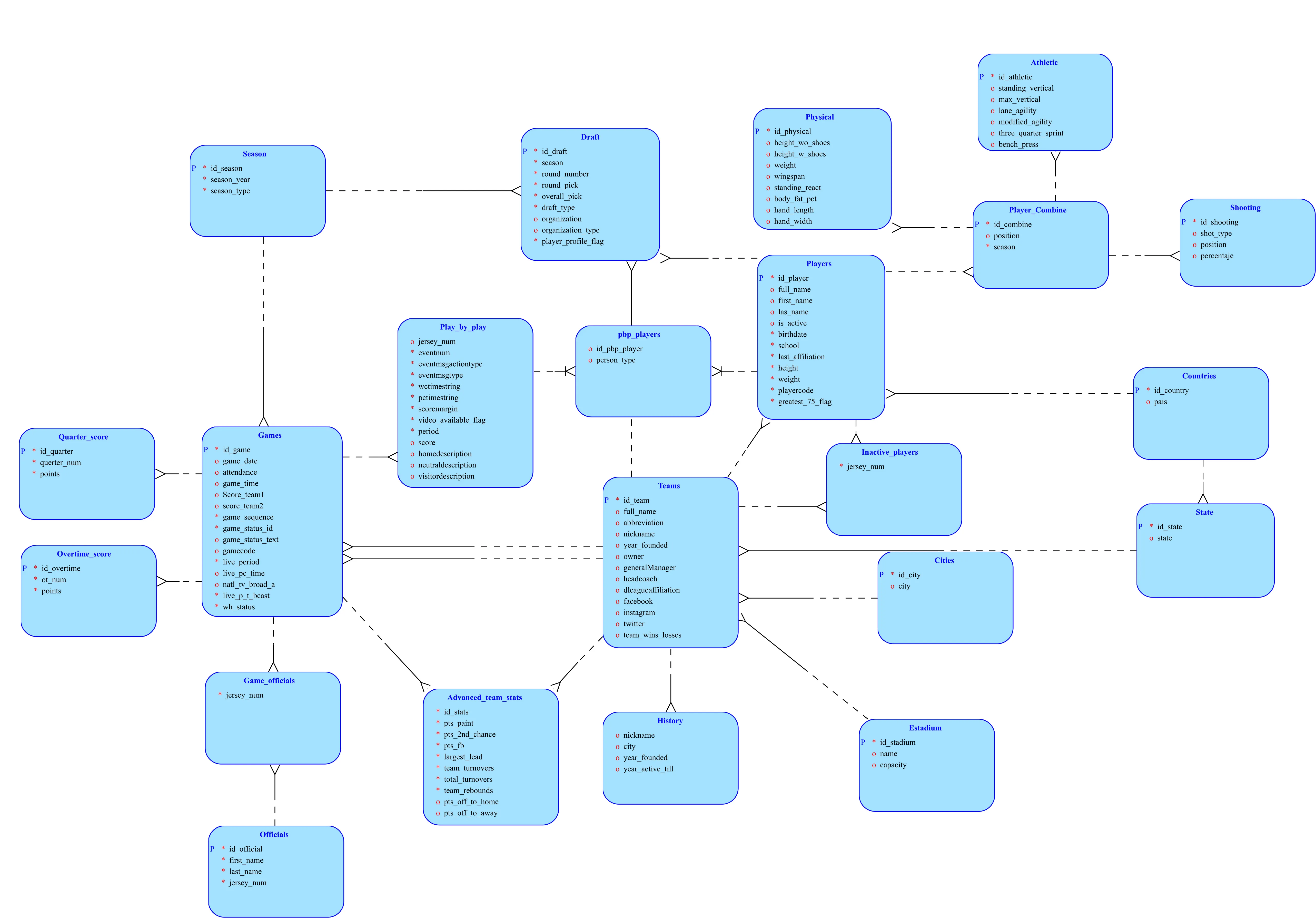
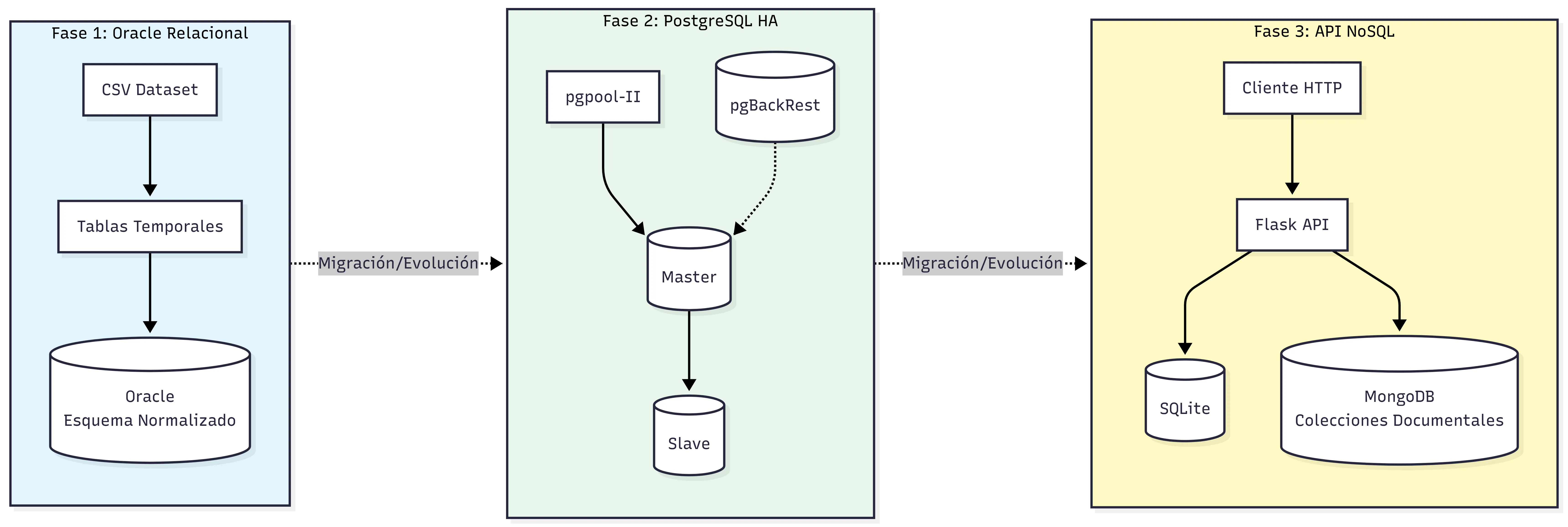

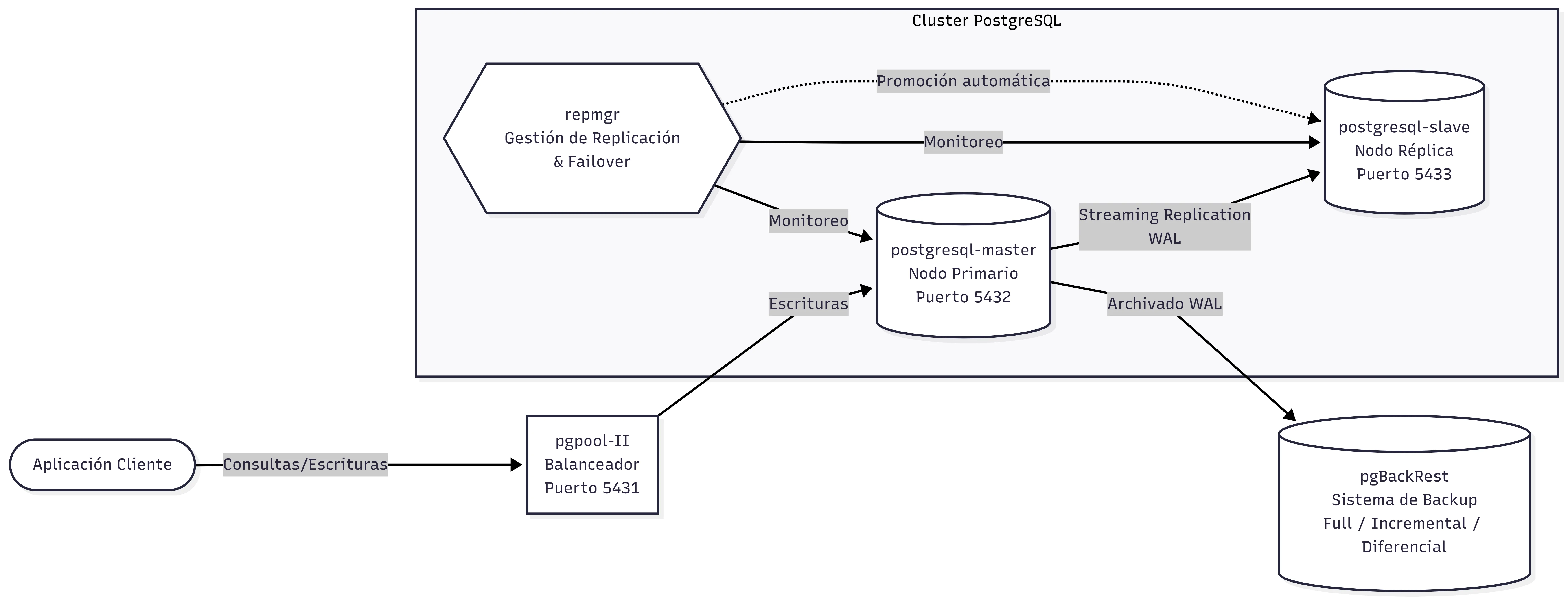

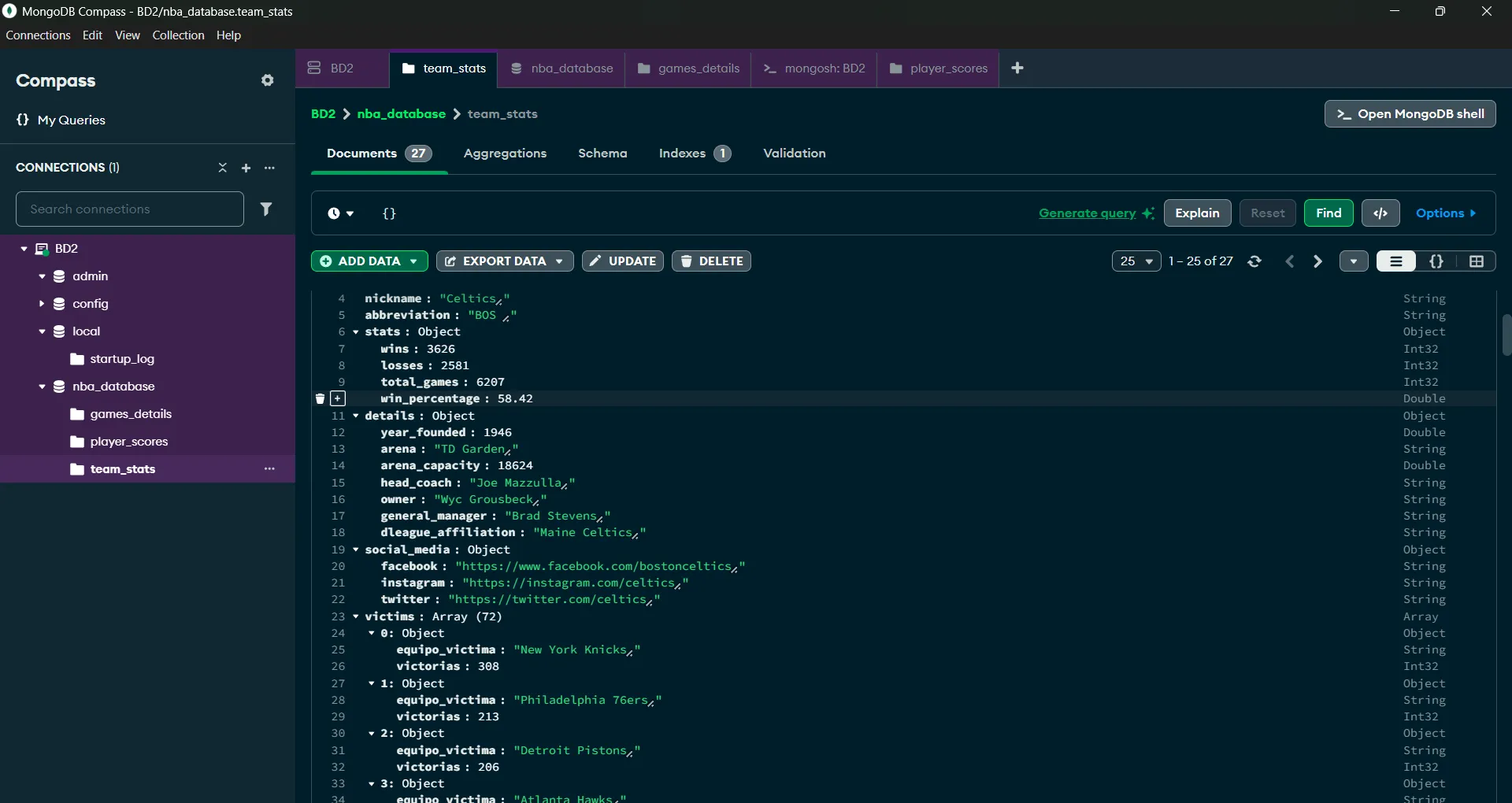
Proyecto académico de alta complejidad técnica dividido en tres fases progresivas que modelan el ciclo de vida completo de ingeniería de datos sobre el Basketball Dataset de Kaggle (~15 CSVs con datos históricos de la NBA). **Fase 1 — Oracle ETL & Modelado Relacional:** Diseño de un esquema normalizado de 17 tablas en Oracle 11g/SQL Developer Data Modeler, incluyendo entidades como Players, Teams, Games, Draft, Play_by_play, Physical, Player_Combine, Season, Officials, entre otras. El pipeline de carga utiliza tablas de staging temporales con triggers AFTER INSERT que orquestan la transformación y distribución de los datos hacia el modelo destino. Se implementaron stored procedures para inserción de datos atléticos y físicos (combinados NBA), funciones Oracle para resolución de entidades (get_or_create_teams), y consultas analíticas complejas (top anotadores, víctimas favoritas por equipo). **Fase 2 — PostgreSQL High Availability con Docker:** Clúster maestro-esclavo sobre PostgreSQL 15 desplegado con Docker Compose, con imagen personalizada que compila pgBackRest desde fuente (meson/ninja). La replicación usa streaming replication + WAL archiving gestionado por repmgr 5. pgpool-II actúa como middleware de balanceo de carga y detección de fallos. Se implementó una estrategia de backup en 3 niveles (full/incremental/diferencial) con pgBackRest, scripts de failover/failback automatizados, y un servicio dedicado de restauración (restore-db) aislado del clúster productivo. **Fase 3 — Flask REST API con Persistencia Políglota (SQLite → MongoDB):** API REST desarrollada en Python/Flask que actúa como capa de migración y consulta entre una base de datos SQLite (fuente de datos NBA histórica) y MongoDB (destino optimizado para consultas). El módulo db_manager implementa queries SQL complejas con CTEs y funciones de extracción de texto para análisis de play-by-play, procesamiento por lotes de 500 registros para evitar límites de variables SQLite, y bulk inserts a MongoDB. Las colecciones MongoDB almacenan estadísticas denormalizadas con documentos JSON jerárquicos (team_stats con subdocumentos details, social_media, victims, stats).
- Diseño de esquema Oracle normalizado iterativo con historial de cambios documentado: migración de tipos BLOB → VARCHAR2, extracción de entidad Physical, separación de Player_Combine con tablas Athletic y Shooting
- Pipeline de carga ETL basado en tablas staging temporales + triggers AFTER INSERT que automatizan la transformación y distribución hacia el modelo destino sin intervención manual
- Imagen Docker personalizada que compila pgBackRest desde código fuente (GitHub) usando meson/ninja dentro del contenedor, sobre base bitnami/postgresql-repmgr:15
- Clúster PostgreSQL 15 con failover automático coordinado entre repmgr (detección y promoción de nodo) y pgpool-II (redirección de tráfico), con script de failback para restaurar la topología original
- Estrategia de backup en 3 niveles con pgBackRest: Full (semanal), Incremental (diario), Diferencial (cada 2-3 días), con retención configurable de 2 backups full
- API Flask con arquitectura dual-source: SQLite como fuente transaccional y MongoDB como capa analítica optimizada para lectura, con endpoints POST para migración on-demand
- Queries SQL avanzadas con CTEs (Common Table Expressions) para extracción de puntuaciones desde texto libre en play-by-play usando SUBSTR/INSTR sobre campos descriptivos
- Procesamiento en lotes adaptativos (batch_size=500) en get_games_data para construir documentos JSON jerárquicos complejos evitando el límite de variables SQLite
- Consultas MongoDB en JavaScript nativo para análisis de top anotadores, ranking de equipos y búsqueda por equipo con operadores $regex y $or
- Modelo relacional Oracle completamente normalizado con integridad referencial garantizada sobre 15+ entidades del dominio NBA, incluyendo historial de equipos, estadísticas combinadas de jugadores y play-by-play
- Infraestructura PostgreSQL con alta disponibilidad real: failover automático sin intervención humana gracias a la integración repmgr + pgpool-II, minimizando el RTO en caso de fallo del nodo master
- Estrategia de backup robusta con tres tipos de respaldo (full/incremental/diferencial) que reduce el RPO y permite restauración punto a punto desde un contenedor aislado dedicado
- Migración exitosa de modelo relacional a modelo documental NoSQL: datos desnormalizados en MongoDB con subdocumentos jerárquicos que optimizan las consultas analíticas frecuentes (stats, victims, social_media)
- API REST funcional que desacopla la lógica de transformación de datos de la capa de almacenamiento, permitiendo cargar bajo demanda cualquier colección desde SQLite hacia MongoDB
- Separación de responsabilidades demostrada a través de db_manager.py como módulo de acceso a datos reutilizable, independiente de la capa de presentación Flask